




La «Gran Depuración»: Empresas que están borrando sus datos de la IA.

Ante el riesgo de la «contaminación» algorítmica, el Data-Out se convierte en la nueva estrategia corporativa. Durante años, la mantra fue «más datos, mejor IA». Pero en 2026, la marea ha cambiado drásticamente. Un número creciente de grandes empresas de diseño, arquitectura, desarrollo de software y entretenimiento están iniciando una «Gran Depuración»: retirando activamente sus bases de datos propietarias de las nubes públicas de entrenamiento de IA. La razón es simple: evitar que los modelos generativos «aprendan» sus secretos industriales y diluyan el valor de su innovación.
El temor a la «IA genérica» El problema es que, si todas las IAs se entrenan con los mismos datos públicos o semi-públicos, el resultado es una homogenización. Las IAs empiezan a producir diseños, códigos o estrategias «genéricas» que carecen de la diferenciación y la chispa que solo la propiedad intelectual bien resguardada puede ofrecer.
- Riesgo de dilución de marca: Si tu estilo arquitectónico o tu código fuente se convierte en parte del «conocimiento» de una IA pública, ¿cómo te diferencias de la competencia?
- Protección de la IP: Las empresas están entendiendo que su verdadero valor reside en la exclusividad de sus datos y la forma única en que estos se utilizan para innovar.
- El costo de la «comodidad»: Enviar tus datos a la nube de un tercero puede ser conveniente, pero el riesgo de que sean absorbidos por modelos que luego compiten contigo es demasiado alto.
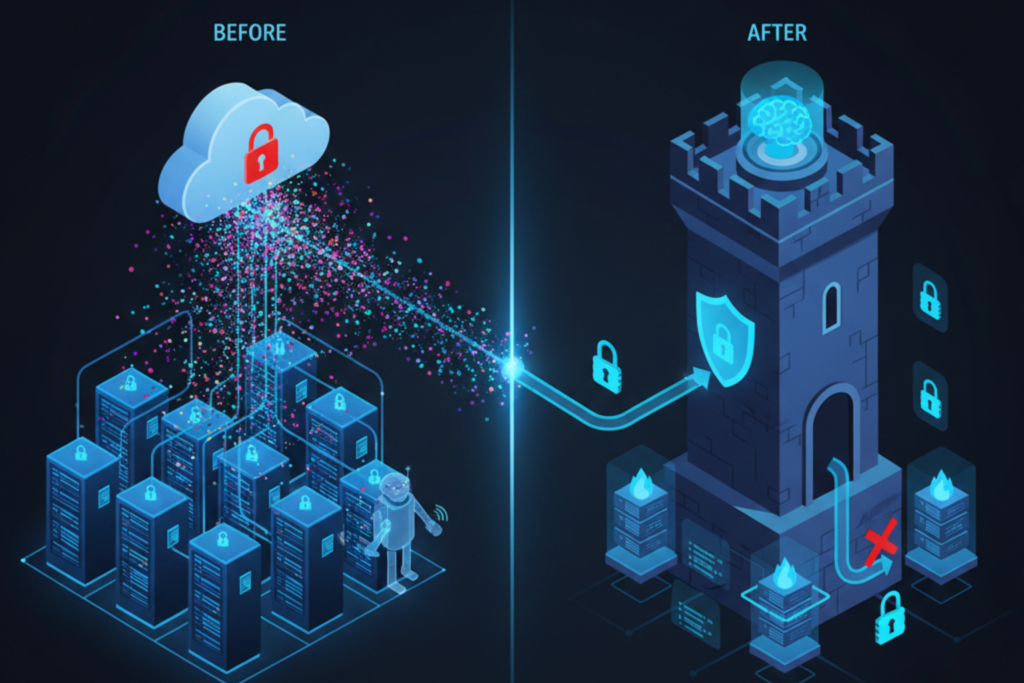
Nubes privadas y el valor del «dato artesanal» La solución para muchas empresas es crear sus propias nubes privadas de IA. Esto implica infraestructuras dedicadas donde los modelos se entrenan exclusivamente con los datos internos, bajo un control riguroso. Este «dato artesanal» se convierte en la ventaja competitiva, permitiendo que la IA de la empresa desarrolle una voz, un estilo o una funcionalidad única que no puede ser replicada por modelos públicos.
«Derecho al Olvido» algorítmico La depuración de datos no es tan sencilla como borrar un archivo. Implica el «Derecho al Olvido» algorítmico, donde las empresas solicitan a los proveedores de modelos grandes que «desaprendan» sus datos específicos. Esto es un desafío técnico inmenso, ya que reentrenar un modelo masivo es costoso y computacionalmente intensivo, pero es una demanda creciente en la industria.
Protege tu propiedad intelectual en la era de la IA. No dejes que tu ventaja competitiva se disuelva en la nube pública. En Geek, te ayudamos a diseñar e implementar estrategias de gestión de datos y arquitecturas de IA que salvaguarden tu propiedad intelectual, permitiendo que tus modelos internos innoven con la exclusividad que tu negocio merece. ¿Quieres asegurar la originalidad de tu innovación? Escríbenos y mantén tus secretos industriales fuera del alcance de la IA genérica.


